Instruction Set
CPU가 다르면 instruction set도 다르다. (그러나 기본적인것은 비슷하다)
많은 현대 컴퓨터들은 simple instruction set를 가짐.
MIPS Instruction Set
임베디드 core market에서 많이 사용된다.
소비자 가전,카메라,프린터, 장비..
Assembly Language Instructions
기계언어. 우리는 하드웨어와 컴파일러를 만들기 쉬운 ISA를 원한다.
RISC - Reduced Instruction Set Computer
RISC의 디자인 철학
- 명령어 길이가 고정적이다
- 로드-스토어 명령어를 이용하여 메모리의 값을 접근
- 주소지정모드가 한정적임
- 연산 개수를 최소화함
컴파일러가 효과적으로 사용할 수 있도록 하는것이 중요하고, 프로그래머가 사용하는것과는 관련x
RISC 네가지 설계 원리
1. 단순하면 정규화하기 쉽다
2. 작은게 빠르다
3. 성능향상에 영향을 많이 주는것을 좋게 만들자
4. 좋은 설계는 적절한 타협이 필요하다
MIPS-32 ISA
명령어 카테고리
- Computational
- Load/Store
- Jumpt and Branch
- Floating Point
- Memory Management
- Special
MIPS는 명령어 포맷이 세가지 존재한다.
R포맷
-----------------------------------------------------------------------------------------------
| opcode (6 bits) | rs (5 bits) | rt (5 bits) | rd (5 bits) | shamt (5 bits) | funct (6 bits) |
-----------------------------------------------------------------------------------------------I포맷
-----------------------------------------------------------------------------------------------
| opcode (6 bits) | rs (5 bits) | rt (5 bits) | immediate(16 bits) |
-----------------------------------------------------------------------------------------------J포맷
-----------------------------------------------------------------------------------------------
| opcode (6 bits) | jump target(26 bits) |
-----------------------------------------------------------------------------------------------
MIPS 아키텍쳐에는 32개의 레지스터가 있기 때문에 rs,rt,rd는 5비트로 표현한다.(2^5=32이므로 5비트로 표현가능)
여기서 RICS설계원칙을 다시 보면
1. 단순하면 정규화하기 쉽다:
- 고정 사이즈의 명령어: 명령어의 크기가 고정되어 있어서 해석이 간단하고 프로세서 설계가 단순해집니다.
- 포맷이 몇 개 없음: R, I, J 포맷의 명령어로 명령어 포맷을 간소화하여 프로세서 설계를 단순하게 합니다.
- opcode는 항상 첫 6비트임: 명령어의 첫 6비트는 명령어 종류를 나타내는 opcode로 고정되어 있습니다.
2. 작은 게 빠르다:
- Operation이 몇 개 없음: 적은 수의 연산을 지원하여 프로세서가 빠르게 동작할 수 있도록 합니다.
- 레지스터가 한정적임: 32개의 레지스터로 제한하여, 레지스터 간의 데이터 이동이 빠르고 효율적입니다.
- 주소지정 모드 한정적임: 간단한 주소지정 모드를 사용하여 메모리 접근을 빠르게 합니다.
3. 성능 향상에 영향을 많이 주는 것을 좋게 만들자:
- 산술 피연산자를 메모리가 아닌 레지스터 파일에서 가져옴: 산술 연산에 필요한 데이터를 메모리가 아닌 고속의 레지스터 파일에서 가져와서 연산을 빠르게 수행합니다.
- Immediate 필드를 이용: 변수에 상수를 더하는 경우, 명령어가 상수를 직접 가지도록 하여 빠른 연산을 가능하게 합니다.
4. 좋은 설계는 적절한 타협이 필요하다:
- 세 개의 명령어 포맷으로 제한함: R, I, J 포맷을 사용하여 간결하면서도 다양한 연산을 지원하는 명령어 세트를 만듭니다.
이러한 설계 원칙들은 MIPS 아키텍처를 통해 간결하면서도 효율적인 컴퓨터 시스템을 구현하기 위한 기준으로 사용됩니다.
MIPS Register File
1. 32개의 32비트 레지스터:
- MIPS 아키텍처에서는 총 32개의 레지스터가 있습니다. 각 레지스터는 32비트 크기를 가지며, 정수 값을 저장하는 데 사용됩니다. 이들은 R0부터 R31까지의 레지스터로 나타내어집니다.
2. 두 개의 읽기 포트 (Two Read Ports):
- 레지스터 파일은 두 개의 읽기 포트를 가지고 있습니다. 이는 동시에 두 개의 레지스터에서 값을 읽을 수 있다는 의미입니다. 이는 한 번에 두 개의 레지스터에서 데이터를 가져와 사용할 수 있다는 장점을 가지고 있습니다.
3. 하나의 쓰기 포트 (One Write Port):
- 레지스터 파일은 하나의 쓰기 포트를 가지고 있습니다. 이는 한 번에 하나의 레지스터에만 데이터를 쓸 수 있다는 의미입니다. 따라서 한 클럭 사이클에는 하나의 레지스터에만 값을 쓸 수 있습니다.
4. 레지스터 vs. 메인 메모리:
- 레지스터는 메인 메모리보다 훨씬 빠릅니다. 이는 레지스터가 CPU 내부에 위치하고 있어서 메모리 버스를 사용하지 않고 직접 액세스할 수 있기 때문입니다.
5. 레지스터 파일 vs. 스택:
- 레지스터 파일은 스택에 비해 컴파일러가 사용하기 더 효과적입니다. 스택은 데이터를 순차적으로 저장하고 불러와야 하지만, 레지스터 파일은 순서에 상관없이 레지스터에 접근할 수 있습니다. 이는 복잡한 계산을 최적화하는 데 도움이 됩니다.
6. 코드 집적도 향상:
- 레지스터 파일을 활용하면 더 효율적인 코드를 작성할 수 있습니다. 레지스터를 사용하여 중간 결과를 저장하고 재사용함으로써 코드의 밀도와 성능을 향상시킬 수 있습니다.
이렇게 된 레지스터 파일은 빠르고 효율적인 데이터 액세스를 가능하게 하며, 프로그램의 실행 속도를 향상시키는 데 중요한 역할을 합니다.
32개의 레지스터
---------------------------------------------------------------
| 이름 | 레지스터 번호 | 사용처 | 함수 호출 시 값 보존 여부 |
---------------------------------------------------------------
| $zero | 0 | 항상 0으로 고정 | - |
---------------------------------------------------------------
| $at | 1 | 예약용 | - |
---------------------------------------------------------------
| $v0~$v1 | 2~3 | 함수 반환 값 | - |
---------------------------------------------------------------
| $a0~$a3 | 4~7 | 함수 인자 | - |
---------------------------------------------------------------
| $t0~$t7 | 8~15 | 임시 레지스터 | 값이 보존되지 않음 |
---------------------------------------------------------------
| $s0~$s7 | 16~23 | 저장 레지스터 | 값이 보존됨 |
---------------------------------------------------------------
| $t8~$t9 | 24~25 | 임시 레지스터 | 값이 보존되지 않음 |
---------------------------------------------------------------
| $k0~$k1 | 26~27 | 예약용 | - |
---------------------------------------------------------------
| $gp | 28 | 전역 포인터 | 값이 보존됨 |
---------------------------------------------------------------
| $sp | 29 | 스택 포인터 | 값이 보존됨 |
---------------------------------------------------------------
| $fp | 30 | 프레임 포인터 | 값이 보존됨 |
---------------------------------------------------------------
| $ra | 31 | 반환 주소 | 값이 보존됨 |
---------------------------------------------------------------
`Caller-saved`와 `Callee-saved`는 함수 호출 시 레지스터 값을 어떻게 다루는지를 나타내는 두 가지 레지스터 저장 규칙입니다.
1. Caller-saved (호출자 저장)
- Caller-saved 레지스터는 함수를 호출한 호출자가 값을 저장하고 복원해야 하는 레지스터입니다.
- 이 레지스터들은 함수 호출 시 값이 덮어씌워질 수 있으므로, 호출자가 필요한 경우 값을 저장하고 복원해야 합니다.
- 주로 임시 결과나 인자 전달에 사용됩니다.
- MIPS 아키텍처에서는 `$t0`부터 `$t9`까지의 레지스터가 Caller-saved 레지스터입니다.
2. Callee-saved (피호출자 저장)
- Callee-saved 레지스터는 호출된 함수 (서브루틴) 내에서 값을 저장하고 복원해야 하는 레지스터입니다.
- 호출된 함수가 호출자의 레지스터 값을 덮어씌우지 않고 유지해야 할 때 사용됩니다.
- 주로 호출된 함수에서 필요한 경우 값을 저장하고 복원합니다.
- MIPS 아키텍처에서는 `$s0`부터 `$s7`까지의 레지스터가 Callee-saved 레지스터입니다.
간단히 말하면, Caller-saved 레지스터는 함수 호출자가 관리하고, 호출된 함수는 그 값을 유지하기 위해 이를 저장하고 복원해야 합니다. Callee-saved 레지스터는 호출된 함수가 관리하고, 호출자는 호출된 함수에 의해 사용되는 레지스터의 값이 변경되지 않을 것을 기대할 수 있습니다.
1. 산술 명령어의 피연산자는 레지스터에 있어야 한다:
- 이 말은 CPU가 수행하는 산술 연산(덧셈, 뺄셈, 곱셈 등)은 주로 레지스터 간에서 이루어진다는 것을 의미합니다. 예를 들어, `ADD $t0, $t1, $t2`라는 명령어는 `$t1` 레지스터와 `$t2` 레지스터의 값을 더해서 그 결과를 `$t0` 레지스터에 저장합니다.
2. 32개의 레지스터로는 모든 데이터를 처리하기에는 부족:
- 32비트 아키텍처에서는 레지스터의 개수가 한정되어 있습니다. 이는 복잡한 연산이나 많은 양의 데이터를 다뤄야 하는 경우에는 부족할 수 있습니다.
3. 메모리는 큰 single-dimensional 배열:
- 메모리는 프로그램이 실행되는 동안 사용할 수 있는 공간입니다. 이를 하나의 큰 배열로 생각할 수 있습니다. 각 배열 요소는 주소를 통해 접근할 수 있습니다.
4. 메모리 주소가 메모리 배열의 index가 될 수 있다:
- 메모리 배열의 각 요소는 주소를 가지며, 이 주소를 사용하여 해당 요소에 접근할 수 있습니다. 예를 들어, 메모리의 첫 번째 요소는 0번 주소, 두 번째 요소는 1번 주소 등으로 접근합니다.
5. 32비트 아키텍처에서 메모리 배열 한 칸은 32비트 = 4바이트 = 1Word:
- 32비트 아키텍처에서 메모리 배열의 각 요소는 4바이트 또는 32비트로 구성되어 있습니다. 이를 한 Word라고 합니다. 이는 주로 한 번에 처리할 수 있는 데이터의 크기를 나타냅니다.
따라서, CPU가 처리해야 할 데이터가 32개의 레지스터로는 부족할 경우, 메모리를 활용하여 더 많은 데이터를 다룰 수 있습니다. 이를 통해 더 복잡하고 대용량의 연산을 수행할 수 있게 됩니다.
MIPS Memory Access Instructions
MIPS 어셈블리 언어에서 사용되는 메모리 접근 명령어들입니다:
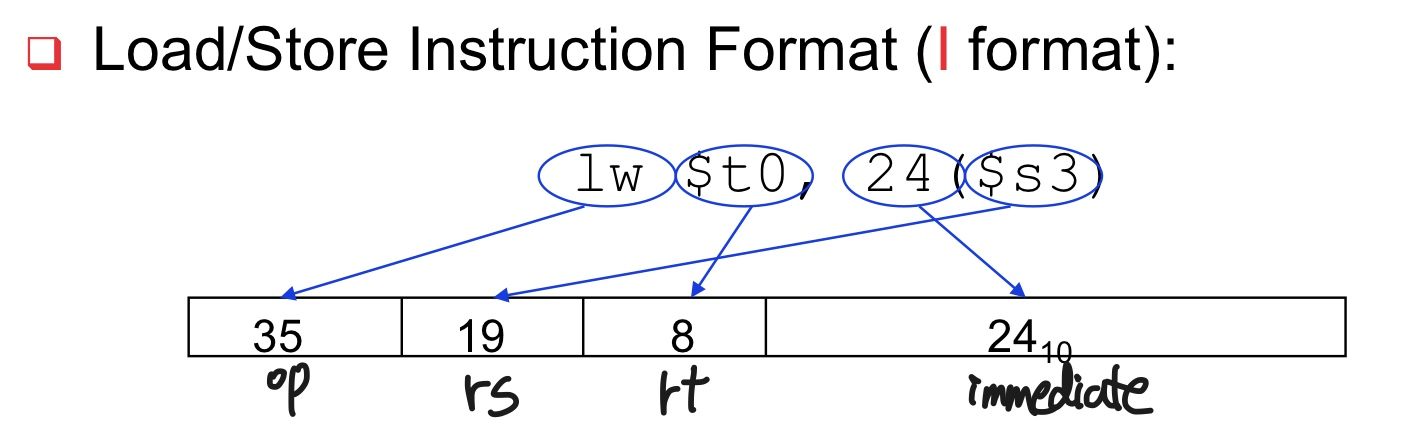
1. lw (Load Word):
- 사용방법: `lw rt, offset(base)`
- 예시: `lw $t0, 100($s0)`
- 설명: `base` 레지스터에 위치한 메모리에서 `offset` 만큼 떨어진 곳의 4바이트 데이터를 읽어와 `rt` 레지스터에 저장합니다.
-----------------------------------------------------------------------------------------------
| opcode (lw) | rs (base) | rt (가져온거 저장할 레지스터) | immediate<- (offset) |
-----------------------------------------------------------------------------------------------
2. sw (Store Word):
- 사용방법: `sw rt, offset(base)`
- 예시: `sw $t0, 100($s0)`
- 설명: `rt` 레지스터의 값을 `base` 레지스터에 위치한 메모리에서 `offset` 만큼 떨어진 곳에 저장합니다.
-----------------------------------------------------------------------------------------------
| opcode (lw) | rs (base) | rt (가져갈 값 있는 레지스터) | immediate<- (offset) |
-----------------------------------------------------------------------------------------------
16비트의 offset은 음수,양수가 가능하다(2의 보수로 음수 표현)
따라서 base주소의 +- (2^15)-1 바이트 범위만큼 지정가능하다.
예를들어
lw $t0, 4($s3)
sw $t0, 8($s3)
명령어가 실행된다고 하자.
$s3에는 8이라는 값이 있을 때,
첫번쨰 lw명령어를 통해 t0레지스터에 8+4=12번지의 메모리값이 저장되고,
두번째 sw명령어를 통해 t0에 저장된 값을 8+8=16번지 메모리에 저장한다.
배열이 있을 때
A[8] = A[2] - b 라는 코드가 있다.
b의 값은 $s2에 저장되어있고, A배열의 base주소는 $s3에 있다.
lw $t0, 8($s3) #t0 레지스터에 A[2] 값을 로드
sub $t0, $t0, $s2 #t0에 A[2]-b값을 넣음
sw $t0, 32($s3) #A[8]에 $t0값 저장
여기서 배열의 한 칸은 크기가 4라는것만 주의하면 된다.
만약 배열의 인덱스가 변수인 경우
c= A[i] - b
# A의 base주소는 $s4, 변수 b,c,i는 각각 $s1, s2, s3이다.
add $t1, $s3, $s3 #i+i 값을 t1레지스터에 저장=> 2*i
add $t1, $t1, $t1 #t1값을 다시 2배함 => 4*i
add $t1, $t1, $s4 #4*i값 + A배열의 베이스주소
lw $t0, 0($t1) #A[i]의 값을 가져옴
...
여기서는 i의 값이 레지스터에 저장되어있으므로, 해당 레지스터의 값을 4번 더해 4*i를 만들어 사용했다.
ASCII코드는 8비트=1바이트이다. 따라서 우리는 바이트단위로 값을 가져오는 명령어도 필요하다.
(참고: word=4바이트)
명령어를 배우기 앞서 빅 엔디안과 리틀엔디안을 알아야한다.
빅 엔디안: MSB를 메모리 시작주소에 적는 방식
리틀 엔디안: LSB를 메모리 시작주소에 적는 방식
1935라는 값을 메모리에 저장한다고 하자.
아래 표는 메모리를 표현한것이고, 가장 왼쪽 칸이 메모리의 시작주소이다.
빅엔디안으로 표현하면 다음과 같다.
| 1 | 9 | 3 | 5 |
리틀엔디안으로 표현하면 다음과 같다.
| 5 | 3 | 9 | 1 |
빅엔디안 방식은 사람이 읽는 방향과 일치하기 때문에 읽기 편하고, human-natural order라고 부른다.
(반대로, 리틀엔디안은 machine friendly라고 하기도 함. 이는 빅엔디안과 반대되는 의미로써 부르는것이지 실제로는 기계는 이러나 저러나 읽는데는 문제가 없다.)
3. lb (Load Byte):
- 사용방법: `lb rt, offset(base)`
- 예시: `lb $t0, 10($s1)`
- 설명: `base` 레지스터에 위치한 메모리에서 `offset` 만큼 떨어진 곳의 1바이트 데이터를 읽어와서 `rt` 레지스터에 부호 확장하여 저장합니다.
4. sb (Store Byte):
- 사용방법: `sb rt, offset(base)`
- 예시: `sb $t0, -5($s2)`
- 설명: `rt` 레지스터의 가장 낮은 1바이트를 `base` 레지스터에 위치한 메모리에서 `offset` 만큼 떨어진 곳에 저장합니다.
이 두 명령어는 byte단위로 메모리의 값을 가져오거나 저장하는점이 다르다.
5. lh (Load Halfword):
- 사용방법: `lh rt, offset(base)`
- 예시: `lh $t0, 20($s3)`
- 설명: `base` 레지스터에 위치한 메모리에서 `offset` 만큼 떨어진 곳의 2바이트 데이터를 읽어와 `rt` 레지스터에 부호 확장하여 저장합니다.
6. sh (Store Halfword):
- 사용방법: `sh rt, offset(base)`
- 예시: `sh $t0, -30($s4)`
- 설명: `rt` 레지스터의 가장 낮은 2바이트를 `base` 레지스터에 위치한 메모리에서 `offset` 만큼 떨어진 곳에 저장합니다.
이 두 명령어도 앞선 명령어들과 유사하고, 가져오는 값의 크기가 half word, 즉 2바이트라는 점이 다르다.
(메모리 한 칸의 주소가 0 1 2 3일때, half word로 가져오려면 0-1 or 2-3 형태만 가져올 수 있다. 1-2 or 0-3은 안됨)
lb,lh,sb,sh에서 base주소+offset하는 과정에서 sign extension이 필요하며,
lb,lh에서 메모리의 값 1바이트/2바이트를 가져와 4바이트의 레지스터에 로드하는 과정에서 zero extension이 필요하다.(메모리의 값 가져올때 부호는 가져오지 않기 때문)
addi
작은 상수 연산은 자주 사용된다.
(A=A+4, B=B+1 등의 상황)
이러한 common case를 개선하기 위해 여러가지 방법을 고안해냈는데,
그중 하나가 "상수를 명령어 안에 넣기"이다.
addi는 I format을 사용한다.
-----------------------------------------------------------------------------------------------
| opcode (6 bits) | rs (5 bits) | rt (5 bits) | immediate(16 bits) |
-----------------------------------------------------------------------------------------------여기서 immediate필드에 상수를 적어 사용할 수 있다.
addi $s3, $s3, 4 처럼 사용.
이 때 상수는 16비트, 레지스터는 32비트이므로 비트확장이 필요한데, 산술연산이므로 sign extension을 한다.
slti
(set less than)
slti $t0, $s2, 15 #t0=1 if $s2<15
이처럼 immdiate 필드에 상수를 16비트 넣어 사용할 수 있다. 상수는 양수,음수가 가능하므로 -2^15-1~+2^15-1 범위까지 표현가능하다.
만약 이 범위를 넘어가는 상수를 사용해야한다면?
lui, ori 두개의 명령어를 이용하면 32비트 상수를 만들 수 있다.
lui, ori
lui (load upper immediate)
상위 16비트를 지정할 수 있는 명령어.
lui $t0, 1010101010101010
(이 때 $t0는 i포맷에서 rt필드로 들어감)
ori: 하위 16비트를 지정할 수 있는 명령어
ori $t0, $t0, 1110111011101110
Sign Extension
extension시 기존의 값은 보존한다.
MIPS에서 extension이 필요한 명령어는...
- addi: 덧셈 비트수 맞추기 위해
- lb, lh: base주소+offset할 때
- beq, bne: 명령어 거리 계산할 때
가 있다.
Shift Operations
logical shift
<< 또는 >> 연산.
이 때, shamt만큼 shift하면, 새로 들어오는 값은 0으로 채워진다.
- sll $t2, $s0, 8 #$t2 = $s0 << 8 bits
sll rd, rt, shamt 순서이다. rs는 사용하지 않는다.
-srl $t2, $s0, 8 #$t2 = $s0 >> 8 bits
srl rd, rt, shamt 순서이다. rs는 사용하지 않는다.

레지스터는 32비트이므로 shamt는 5비트로 32까지 표현가능하다.
arithmetic shift
부호를 맞추면서 쉬프트한다.
>> 하면 값이 1/2씩 감소,
<<하면 값이 2배씩 증가한다.
<<연산에서는 부호쪽에 새로운 값이 들어오는게 아니기때문에 0으로 채우는데, 이는 logical shift와 동일하므로 sla는 필요없다. sll 사용해라.
sra
sra $t2, $s0, 8 #$t2 = $s0 >> 8 bits

MIPS Logical Operations
- and
- or
- nor
---위는 R포맷---
---아래는 I포맷---
- andi
- ori
여기서 NOT 명령어는 없다.
$zero와 NOR연산을 하면 NOT이 되기 때문이다.
그리고 binary operate라서 NOR이 더 빠름.
Instructions for Making Decisions
(if문 등 분기 처리)
실행흐름, control flow를 변경한다.
조건 분기 명령어
1. bne (Branch if Not Equal):
bne 명령어는 두 레지스터의 값이 서로 다를 때 분기합니다. 즉, 첫 번째 레지스터와 두 번째 레지스터의 값이 다르면 지정된 오프셋만큼 분기합니다.
bne $t0, $t1, label
이 명령어는 `$t0`와 `$t1`의 값이 서로 다르다면 `label`로 분기합니다.
2. beq (Branch if Equal):
beq명령어는 두 레지스터의 값이 서로 같을 때 분기합니다. 즉, 첫 번째 레지스터와 두 번째 레지스터의 값이 같으면 지정된 오프셋만큼 분기합니다.
beq $t0, $t1, label
이 명령어는 `$t0`와 `$t1`의 값이 서로 같다면 `label`로 분기합니다.
이 두 명령어는 I포맷을 사용한다.
순서대로 op rs rt immediate 필드이다.
이 때, immediate 필드 16비트는 branch distance를 기입한다.
이는 현재 명령어 기준으로 브랜치까지의 거리이다.
PC는 항상 다음 명령어를 가리키고 있고,
한 명령어의 크기는 무조건 4이다.
명령어 주소는 0,4,8,12 ... 처럼 표현되는데, 이를 이진수로 나타내면
0000
0100
1000
1100
... 이다.
여기서 뒤 2비트는 항상 0이 되기 때문에, 해당 비트는 제외한 16비트만을 immediate 필드에 기입한다.
그럼 immediate필드는 16비트이지만 사실상 18비트를 사용하는것과 같은 효과이고,
PC기준 +- 2^17바이트=+-2^15워드 범위만큼 지정가능하다.
주의: high-level에서의 조건이 if(i==j)인 경우, beq이 아닌 bne i j 를 사용한다.
if문 통과시 바로 아래에 있는 문장을 실행하는데,
if문을 통과하지 못하는 경우에 분기해야하기 때문이다.
따라서 고레벨언어의 조건과 반대로 사용해야함.
추가로, 분기의 조건으로는 ==, != 말고도 대소비교가 필요할 수 있다.
이 때는 slt 명령어를 이용하면 된다.(slt말고도 slti, sltu, sltiu도 있음)
예를들어 $s1<$s2인 경우 분기한다면
slt $at, $s1, $s2
bne $at, $zero, Label
처럼 나타내면 된다.
따라서 blt, ble, bgt, bge는 ISA에는 실제로 포함되어있지 않고 사람이 읽기 편하도록 pesudo instruction으로 사용된다.
(해당 명령어들을 모두 만들면 명령어가 많아져 복잡해지며, 결국 작은명령어 여러개를 붙인것이므로 클락사이클이 길어져 느려질수 있음)
Unconditional Jump
조건 없이 점프하는 명령어.
goto 문에 의해서 사용되기도 하지만, goto를 사용하지 않더라도 일반적인 if-else에서도 사용된다.
(if절 끝에서는 다음 문장인 else를 실행하는게 아니라 if-else다음 명령어를 실행해야하기 때문)
j Lbl 형식으로 사용한다.
J포맷이며, 앞의 opcode 외의 26비트는 모두 명령어주소라벨로 사용됨.
bne, beq과 마찬가지로 branch distance는 하위2비트를 제외하고 기입한다.
=> 26비트 + 2비트 = 28비트
그리고, PC의 상위4비트를 가져와 합친다. => 28+4비트 = 32비트.
이렇게 j명령어를 이용하면 bne, beq보다 훨씬 넓은범위로 점프가 가능하다.
만약, beq, bne에서 immediate 필드 16비트가 부족한 경우는 j명령어를 사용할 수 있는데,
원래의 명령어가 beq $s0 , $s1, L1이라면
bne $s0, $s1, L2
j L1
L2: next ins. of beq
로 변경할 수 있다.(기존의 beq조건 성립시 j L1을 실행하며, 기존의조건이 성립하지 않은 경우 j L1을 실행하지 않기 위해 bne를 이용하여 기존명령어 beq의 다음 명령어가 있는 곳으로 분기하도록 함)
'2023-2 > 컴퓨터 구조' 카테고리의 다른 글
| Processor Architecture (0) | 2023.10.29 |
|---|---|
| 컴퓨터 구조의 핵심 개념과 성능 최적화 전략 (0) | 2023.10.03 |
댓글